En beredskabsplan er ikke et dokument, man skriver for revisionens skyld; den er et operationelt værktøj, der skal fungere under pres, når systemer er nede, kunder spørger, og beslutninger skal træffes hurtigt. I denne artikel får du et praktisk fundament baseret på Nesp.ONEs beredskabsplan-vinkel: trusselvurdering i selve planen, klare playbooks, tydelige roller, logning og beviser samt en øvelsesrytme, der gør jer reelt klar til hændelser.
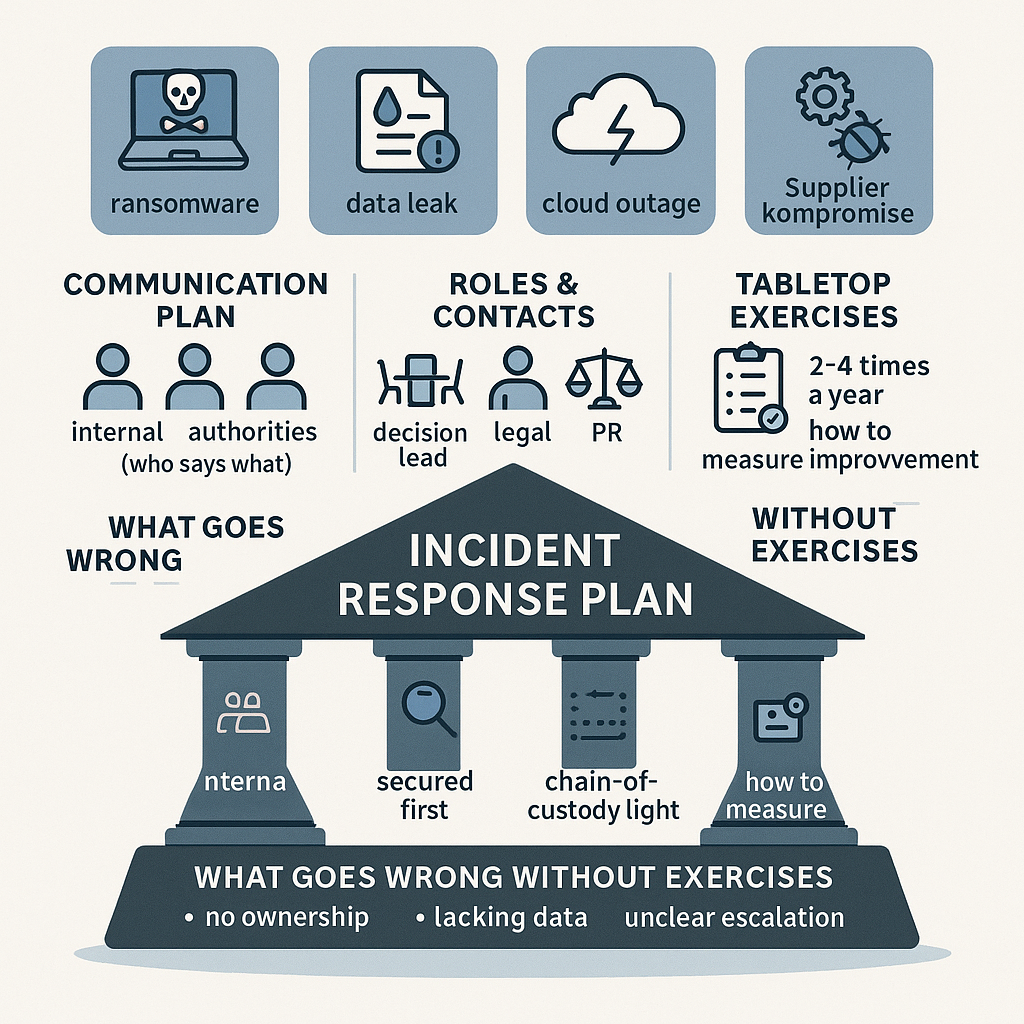
Du får konkrete takeaways: minimum fire playbooks (ransomware, datalæk, cloud outage og leverandørkompromis), en kommunikationsplan for interne interessenter, kunder, myndigheder og presse, og en metode til tabletop-øvelser 2–4 gange årligt, så planen bliver bedre for hver runde.
Hvad en beredskabsplan er, og hvorfor den betyder noget
En beredskabsplan er en struktureret beskrivelse af, hvordan I opdager, håndterer og lærer af it- og sikkerhedshændelser, så skaden begrænses, og driften genoprettes. Den betyder noget, fordi tidlige beslutninger ofte bestemmer både nedetid, tab og tillid. Uden plan ender teams i ad hoc-arbejde, dobbeltarbejde og usikre vurderinger.
Planen skal bygge på en trusselvurdering: Hvilke hændelser er realistiske, hvilke systemer er mest kritiske, og hvor er jeres største afhængigheder? Når trusselvurderingen er integreret, kan I prioritere playbooks, logging og kommunikation, så indsatsen matcher jeres risikoprofil.
Mini-konklusion: En god plan er ikke lang; den er brugbar, prioriteret og testet i forhold til jeres reelle trusler.
Trusselvurdering i planen: fra “muligt” til “sandsynligt”
Mange spørger: “Hvordan laver vi en trusselvurdering, der faktisk hjælper?” Start med at koble tre ting: kritiske forretningsprocesser, tekniske afhængigheder og sandsynlige angriberveje. Det er her, beredskabsplanen bliver skarp: Den fortæller ikke alt, men det rigtige.
Praktisk metode til at prioritere scenarier
Lav en enkel matrix, hvor I vurderer sandsynlighed og konsekvens for 8–12 hændelsestyper. Tag derefter de fire øverste som minimum-playbooks, og lad de næste fire ligge som “udvidet beredskab”. Inkludér også “single points of failure” som IdP, DNS, M365, betalingsflow og kritiske leverandører.
Hvad koster det, og hvad er “nok”?
Omkostningen handler mindre om værktøjer og mere om timer: workshops, dokumentation og øvelser. For en mindre organisation kan en første version ofte laves på få uger med korte sessioner; større miljøer kræver flere interessenter og mere koordinering. “Nok” er, når I kan svare på: Hvem beslutter, hvem gør hvad, hvornår informerer vi, og hvordan genskaber vi drift?
Mini-konklusion: Trusselvurdering er ikke et separat bilag; den er motoren, der bestemmer planens fokus og niveau af detaljer.
Minimum playbooks: fire scenarier, I altid bør kunne køre
Playbooks er jeres “trin-for-trin” forløb, der kan følges i en war room-situation. De skal være korte nok til at bruges og præcise nok til at styre handling. Hver playbook bør have: trigger/indikatorer, første 60 minutter, stabilisering, gendannelse, kommunikation og efterbearbejdning.
- Ransomware: isolér, stop spredning, bevar beviser, vurder gendannelse kontra forhandling.
- Datalæk: afgræns eksponering, identificér datatyper, vurder anmeldelsespligt og kundepåvirkning.
- Cloud outage: fastslå scope, failover-plan, kundekommunikation, prioritering af services.
- Leverandørkompromis: stop integrationer, roter nøgler, verificér leverandørens status og jeres egen påvirkning.
- Misbrug af legitim adgang: suspender konti, gennemgå logs, styrk MFA, intern undersøgelse.
- DDoS eller tilgængelighedsangreb: trafikfiltrering, kontakt ISP, status-side og timeboxing.
De fire første er jeres minimum. De ekstra scenarier kan tilføjes, hvis de scorer højt i trusselvurderingen. Hold playbooks i samme format, så teamet ikke skal “læse sig varmt”, når det gælder.
Mini-konklusion: Hvis I kan køre de fire minimum-playbooks sikkert, har I et robust udgangspunkt for de fleste kritiske hændelser.
Ransomware-playbook: de første 60 minutter og de næste 48 timer
Ransomware handler om tempo og disciplin. I de første 60 minutter er målet at begrænse spredning, sikre beviser og få overblik over påvirkede systemer. Beslutninger om betaling må aldrig træffes af teknikere alene; det er et ledelses- og juridisk spørgsmål.
Første 60 minutter: isolér og bevar
- Aktivér war room og udpeg beslutningstager og teknisk lead.
- Isolér berørte segmenter: netværk, endpoints og konti; stop planlagte jobs.
- Sikr volatile data hvor muligt: processer, netværksforbindelser, RAM-baserede indikatorer.
- Frys ændringer: begræns admin-aktiviteter til et lille team og log alt.
- Bekræft backup-status og seneste “known good” restore-punkt.
De næste 48 timer: gendannelse og kommunikation
Fokus skifter til gendannelse, rotér credentials, fjern persistence og byg et “rent” miljø til restore. Samtidig skal kommunikation ske koordineret, så I ikke lover mere, end I kan holde. Den typiske fejl er at genåbne for tidligt og blive ramt igen, fordi root cause ikke er fjernet.
Mini-konklusion: Ransomware er et maraton i sprinttempo; gendannelse uden årsagsfjernelse er en invitation til geninfektion.
Datalæk og leverandørkompromis: klassificér data og styr kæderne
Ved datalæk er det afgørende at klassificere data hurtigt: persondata, fortrolige forretningsdata, adgangsoplysninger eller kildekode. Ved leverandørkompromis skal I antage, at integrerede tokens, API-nøgler og SSO-forbindelser kan være påvirket, indtil andet er bevist.
Datalæk: hvad I gør først
Start med at stoppe lækagen, ikke med at forklare den. Luk eksponerede buckets, fjern offentlig adgang, og bevar logs og snapshots. Vurdér derefter omfang: hvilke datasæt, hvor længe, og om data er exfiltreret eller blot eksponeret. Her kommer “hvilke fejl” ofte: teams sletter beviser i iver efter at “rydde op”, eller kommunikerer før de ved, hvad der er sket.
Leverandørkompromis: kontrol over jeres egen side
Kontakt leverandøren, men arbejd parallelt: deaktivér integrationer, roter nøgler, gennemgå adgangslogs og begræns privilegier. Inkludér en klar beslutningsregel i playbooken: hvornår I afbryder dataflow, og hvem der godkender det. Midt i planarbejdet kan det være nyttigt at orientere sig mod krav og forventninger, fx via NIS2 beredskabsplan, så jeres procedurer hænger sammen med governance og rapportering.
Mini-konklusion: Datalæk kræver præcision i klassificering og beviser; leverandørkompromis kræver, at I kan lukke for kæderne uden at miste overblikket.
Cloud outage-playbook: drift, prioritering og kundeløfter
Cloud outages sker også for modne leverandører. Det svære er ikke at erkende nedetid, men at styre afhængigheder: identitet, netværk, databaser, køsystemer og tredjeparts-API’er. En god playbook beskriver, hvordan I prioriterer forretningskritiske services og håndterer “partial failure”, hvor alt virker for nogle kunder, men ikke for andre.
Start med en teknisk triage: er det jeres konfiguration, regionen, eller en upstream-tjeneste? Definér en “status cadence”: opdateringer hver 30–60 minutter til interne kanaler og en fast rytme til kunder. Den typiske faldgrube er at love en ETA uden data; brug i stedet tidsbokse og scenarier: “vi undersøger”, “vi har workaround”, “vi er i restore”.
Mini-konklusion: Ved cloud outage er gennemsigtig prioritering og stabil kommunikationsrytme vigtigere end perfekte svar.
Kommunikationsplan: internt, kunder, myndigheder og presse
Kommunikation skal være en del af beredskabsplanen, ikke en eftertanke. Spørgsmålet “hvem siger hvad?” skal være besvaret på forhånd, ellers opstår der modstridende budskaber, og tekniske detaljer ender i forkerte kanaler.
- Internt: teknisk lead opdaterer war room; beslutningstager kommunikerer impact og prioriteringer til ledelse.
- Kunder: en udpeget kundeansvarlig og PR udarbejder status-tekst med faktuelle punkter og næste opdateringstid.
- Myndigheder: juridisk og DPO vurderer anmeldelsespligt, frister og dokumentationskrav.
- Presse: kun PR eller udpeget talsperson udtaler sig; teknikere udtaler sig ikke ad hoc.
- Partnere: vendor manager koordinerer bekræftelser, mitigering og fælles tidslinje.
Indfør skabeloner: “første statement”, “løbende status” og “afsluttende opdatering”. Hold jer til fakta, kendt impact, og hvad I gør nu. Best practice er at have en intern “single source of truth”, så alle bygger på samme status.
Mini-konklusion: Kommunikation er incident response; den beskytter tillid og køber tid til teknisk udbedring.
Roller, kontaktlister og war room: så eskalering ikke bliver kaos
En beredskabsplan uden navne og kontaktveje bliver hurtigt teoretisk. Opret en war room-model med en klar kommandovej og back-ups. Roller bør være knyttet til funktioner, men også til konkrete personer, så I ikke står uden ejerskab klokken 03.
Minimum-roller:
- Beslutningstager: prioriterer forretning, godkender større ændringer, accepterer risiko.
- Teknisk lead: styrer triage, mitigering og gendannelse, fordeler opgaver.
- Incident coordinator: tidslinje, møder, actions, status cadence og dokumentation.
- Juridisk/DPO: vurderer persondata, kontrakter, underretning og beviskrav.
- PR/kommunikation: budskaber, Q&A, pressehåndtering og kundetekster.
- IT drift/sikkerhed: logindsamling, kontroller, hardening og overvågning.
Kontaktlisten skal ligge to steder: et sikkert digitalt sted og en offline-kopi. Inkludér leverandører, SOC, forsikring, ekstern IR-partner og kritiske interne stakeholders. Faldgruben er forældede numre; sæt en kvartalsvis reminder til opdatering.
Mini-konklusion: Roller og kontaktlister er den billigste måde at reducere responstid på, fordi de fjerner tøven og gætterier.
Beviser og logging: sikr det rigtige først, og hold styr på kæden
Når en hændelse rammer, er der to parallelle behov: at få driften op igen og at kunne forklare, hvad der skete. Bevisindsamling behøver ikke være tung digital forensics, men den skal være konsekvent. Brug en “chain-of-custody light”: hvem indsamlede hvad, hvornår, hvor er det gemt, og hvem har adgang.
Hvad sikres først afhænger af scenariet, men typisk:
- SIEM- og auditlogs fra IdP, M365, VPN, firewall og EDR.
- Snapshots eller images af kompromitterede servere, hvis muligt uden at ødelægge drift.
- Cloud control plane-logs (API-kald, IAM-ændringer, storage access).
- Mail headers, phishing-artefakter og mistænkelige vedhæftninger.
- Tidslinje: første observation, handlinger, beslutninger og ændringer.
Den typiske fejl er at overskrive logs eller rotere nøgler uden at notere tidspunkter. Et simpelt incident-ark med tidsstempler kan gøre forskellen mellem klarhed og kaos.
Mini-konklusion: God logging og let kædekontrol gør jer hurtigere nu og klogere bagefter, uden at stoppe arbejdet.
Tabletop-øvelser 2–4 gange årligt: sådan tester I og måler forbedring
Øvelser er det, der gør planen levende. Tabletop-øvelser kræver ikke fuld nedlukning; de kræver realistiske scenarier, de rigtige deltagere og en facilitator, der presser på med “hvad gør I nu?”. Planlæg 2–4 øvelser om året: to standardscenarier og én overraskelsesøvelse, plus en kort “kommunikationsdrill”.
Årshjul og format
Hold dem korte og fokuserede: 60–120 minutter. Skift mellem ransomware, datalæk, cloud outage og leverandørkompromis, så alle playbooks bliver brugt. Brug artefakter: falske logudsnit, kundemail, presseforespørgsel og en myndighedsfrist, så tempoet føles ægte.
Målepunkter: sådan ser I, at I bliver bedre
Mål ikke kun “følelse”; mål adfærd. Registrér tid til war room, tid til første interne status, tid til kundebesked, og om roller blev fulgt. Track også kvalitet: antal uafklarede beslutninger, manglende kontaktoplysninger, og om logging blev sikret korrekt. Efter hver øvelse laver I en kort handlingsliste med ejere og deadlines, og næste øvelse starter med at tjekke lukning.
Mini-konklusion: Øvelser gør planen kortere, skarpere og mere realistisk, fordi I fjerner det, der ikke virker i praksis.
Hvad der går galt uden øvelser: ejerskab, data og eskalering
Uden øvelser får I en plan, der ser rigtig ud, men fejler i det øjeblik, den bliver brugt. Det første der går galt er ingen ejerskab: ingen tør beslutte nedlukning, kommunikationen bliver fragmenteret, og teknikere ender som uofficielle talspersoner. Det andet er manglende data: logs er ikke tilgængelige, retention er for kort, og beviser bliver overskrevet i oprydningen. Det tredje er uklar eskalering: war room aktiveres for sent, kontaktlister er forældede, og leverandører får modstridende beskeder.
Øvelser afslører de stille fejl, før de bliver dyre: uklare roller, u



